Switching from AWS MSK with Confluent to MSK Serverless with Segmentio
Context
Imprint uses Kafka for streaming realtime data into our data warehouse, along with asynchronous processing. This data includes updates to database entities, external events, webhook payloads, audit logs, and important internal metrics. Before this migration, we used AWS Managed Streaming for Kafka (MSK), and Confluent’s Kafka Go library. This worked fine but had a few key issues that motivated us to switch to AWS Serverless MSK and Segment.io’s Kafka Go library.
- Maintenance: We needed to manually handle upgrades to new Kafka versions, and increases to instance type and storage size. Our usage of Kafka was growing as we added new topics, producers, and consumers, along with launching new brand partners with more users and transaction volume.
- Cost Efficiency: Early on, we could afford to be on the smallest instance size, with less storage. As Kafka usage increased, we grew out of smaller tiers and ended up overpaying for a time after each upgrade.
- Performance: The latency between producing a message and consuming it was consistently around 50 milliseconds. During deployments, consumer group rebalances took over 5 minutes, and during load testing, latency would spike to up to 50 minutes. Based on this performance comparison, we expected a significant improvement from segmentio/kafka-go. In addition, Confluent’s library is based on librdkafka, a C library, which incurred a significant memory utilization overhead for us.
- Authentication: We wanted to leverage IAM Authentication. For one this is required for MSK serverless, but it also makes our environment more secure by giving finer-grained access to each of our microservices. This is something that the maintainer of librdkafka does not intend to support (github comment), so we needed to switch libraries to support this feature.
Given the maintenance and cost efficiency concerns, we decided to go with MSK serverless which then required the usage of IAM-based authentication and necessitated the switch to segmentio/kafka-go. Little did we know that this would be the source of one of our biggest challenges during and after the migration.
Challenges
IAM Reauthentication
We follow AWS’ recommended practice for allowing our microservices to authenticate with MSK serverless (link). This means we use AssumeRoleWithWebIdentity, which has side effects we weren’t initially aware of. Namely, the default maximum session duration for AssumeRoleWithWebIdentity is 1 hour, and the maximum possible session duration is 12 hours. Kafka will respect the session expiration provided with the credentials during the IAM authentication handshake and actually terminate the connection if it lasts longer than this duration. In the beginning, our consumer groups would rebalance every 1 hour, which surfaced to us as unexplained latency spikes. Tracking this issue down and getting it to a (mostly) working state taught us many lessons.
Identifying the Issue
Our first step toward resolving this was realizing that the connections were being killed. If the consumer group heartbeat failed for any reason (i.e. the credentials expired), this would result in the consumer leaving and rejoining the group, without any error logs from segmentio/kafka-go. If the leader of the consumer group had this heartbeat failure, then a consumer group rebalance would be triggered. During a rebalance, the consumers whose credentials hadn’t expired yet would leave and rejoin the consumer group without the IAM credentials being refreshed. Then they would expire after the rebalance was complete, and this would often lead to back-to-back rebalances at around the same time. Another factor was we had around 120 consumers (40 topics, 3 partitions each) in our biggest consumer group, which made the rebalances take longer.
In our testing environment, Kafka events were much more sparse, so we didn’t always see errors or latency spikes tied to rebalances. This made tracking down this issue even more difficult. When we did however, we saw the connection failures were taking a long time to recover, so our first instinct was to adjust the configuration for our consumers, specifically the ReadBackoffMin/ ReadBackoffMax, RebalanceTimeout, SessionTimeout, and JoinGroupBackoff. Ultimately this made the issue worse, as we saw cascading errors due to rate limits from the serverless cluster (MSK Serverless Quota). We needed to take a step back and look at the deeper root cause, which is how we discovered the IAM authentication limits.
Resolution
By increasing the maximum duration to 12 hours, we significantly reduced the frequency of rebalances, but this wasn’t enough. Every 12 hours we had long and expensive rebalances, and the potential for a cascading failure that would lead to a DDOS of our serverless cluster. We needed a way to reduce the rebalance time, so we split our topics into multiple consumer groups per service. This helped, and we further split the consumer groups into one per topic per service, but rebalances still took far too long.
In order to manage the issues, we began to dive deeper into understanding the segmentio library, and realized that it operates under the assumption that rebalances are very rare, and that authentication does not expire (link).
// NOTE : could try to cache the coordinator to avoid the double connect // here. since consumer group balances happen infrequently and are // an expensive operation, we’re not currently optimizing that case // in order to keep the code simpler.
Ideally, the existing connections would have their authentication refreshed without needing to disconnect and reconnect. Unfortunately, this ideal wasn’t achievable without a change to the segmentio library to support KIP-368.
However, we didn’t need to just allow connections to fail. We took back control of the situation by periodically resetting the consumers and refreshing the authentication. We keep track of which consumer is the leader of its consumer group by processing the log messages that are emitted by the Kafka reader. The leader of the consumer group will be fully “reset” (close the Kafka reader, create a new Kafka reader with fresh credentials) just before its authentication expires. The other consumers just need to have the credentials refreshed, because they will be forced to leave and rejoin during the rebalance. Finally, we stagger the controlled resets to be spaced 2 minutes apart for each topic, in order to avoid the rate limiting.
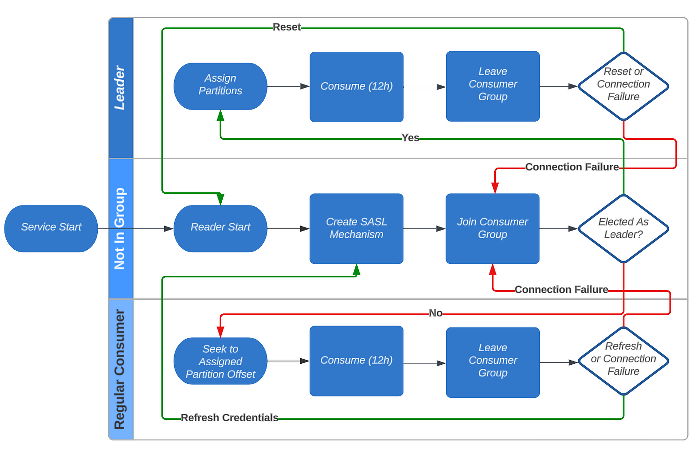
Managing Connections
We knew how we configure our Transport for our Kafka Producer would significantly affect the performance of our system. For context, in the Go documentation’s words
A Transport is a low-level primitive for making HTTP and HTTPS requests.
This is the lowest level of control we can have on our HTTP clients, and fantastically, Segmentio gives us some control on their wrapper for Transport. So, we benchmarked multiple strategies to conclude what would be the best for our workloads. We identified 2 ways to configure how we will manage connections to our Kafka cluster:
- How to handle idle connections?
- How to distribute Transports among the Producers?
How to handle idle connections?
We quickly realized that even though Segmentio gave us control of IdleTimeout, this was not enough. This is because utilizing AWS MSK Serverless meant they could close connections as they see fit or simply as the nature of serverless, the connection to an existing cluster would move to a new IP address. So we utilized the next best strategy: dummy traffic! Later below we compare the 2 major optimizations we chose over the naive configuration.
How to distribute Transports among the Producers?
We needed to pick a strategy for writing messages to our cluster. Do we have each of our microservices use 1 Transport, and all messages are sent through this Transport? Or do we allow each Producer since they are only assigned to 1 Topic have its own Transport? The results were clear when running our pipelines in shadow mode in production. Average P99 latency dropped by over 90% from the naive configuration.
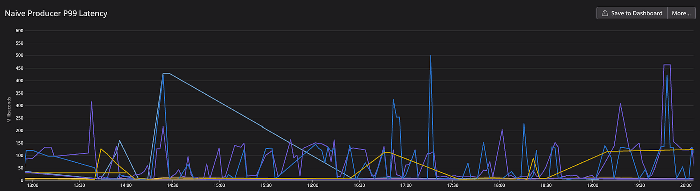
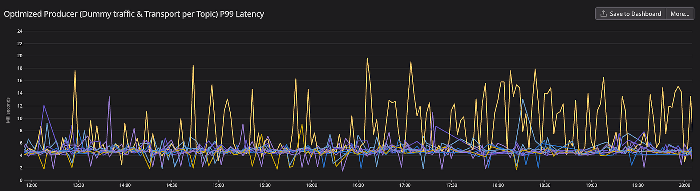
The Switch
Migrating between two solutions while you have multi-faceted dependencies on both the consuming and producing sides is not trivial. With the cascading failures we experienced during the initial testing phase, it wouldn’t be responsible to completely switch over without a transitional period. Our plan was:
- Produce and consume events to both the old cluster+library and the new cluster+library. This was a sequential rollout for each service and its associated topics.
- Verify that the event archive for each cluster had the same events.
- Switch the source of truth for each consumer from the old stream pipeline to the new stream pipeline.
- Turn off the old pipeline.
For the producers, we created an adapter layer that would convert the message format for each library and produce to each cluster in parallel. We used feature flags to determine a primary and secondary library, and this is how we configured those flags for the rollout:

For the consumers, we initialized two consumers for each topic, and depending on the use case, we either replicated the processing or discarded the duplicate messages. For the consumers that couldn’t tolerate duplicate processing, we then rewinded the stream to account for the messages that were skipped during the switchover.
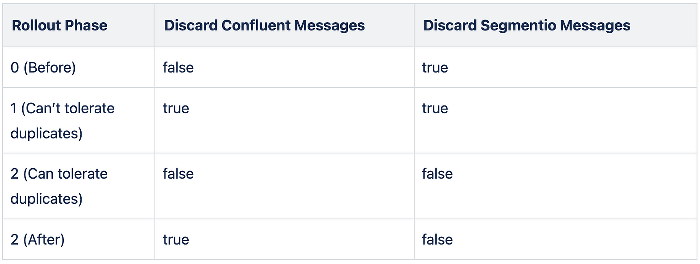
Our main archive consumer looked very similar to the producer rollout, except that “primary” and “secondary” determined which stream would write into our primary and secondary data archives. However, this process was not as smooth as we planned for. Our production environment has much more consistent traffic, and this rollout coincided with the launch of our biggest brand partner yet, HEB. Very quickly we began to see the same cascading failures for production, but with the main streaming pipeline intact, this did not have any business impact. We now believe that the staging serverless cluster where we ran load testing was “warmed up”, while the production serverless cluster was not scaled to handle the load. We added a new feature flag to slow down the archive consumer rollout and turn on the secondary consumption for individual topics. We would enable consumption as the service that produced messages for the topic was switched over.
This migration was slow, but accomplished two major changes at once: the library change and the cluster switch. Looking back, we now know that we should have separated these into two separate rollouts. First, we could have kept the same MSK cluster and authentication while switching from Confluent’s Kafka library to the Segmentio library. Most of the challenges that we faced during the migration were due to the change to serverless MSK, including the frequently expiring IAM authentication and closing connections on our transport. This migration would have been relatively quick, as we wouldn’t have run into the same IAM authentication issues. Later, the infrastructure migration would have faced similar challenges, but we wouldn’t have conflated issues caused by the library with issues caused by the serverless infrastructure and IAM authentication. With the easier root causing, it’s possible that it might have taken less time to complete these two migrations separately.
This project took longer than expected, and each time we faced a new unknown that set us back, it became a possibility that the migration would be scrapped altogether. The opportunity cost of this tradeoff was much more expensive because these migrations were combined into one. Looking back, the biggest takeaways we have for a large migration like this are:
- Run your existing solution and new solution in parallel, then switch over when the new solution is working.
- If possible, split the migration into smaller deliverable components. Don’t try to change too much at once.
Gotcha’s
Connecting Multiple VPCs to our MSK Serverless cluster
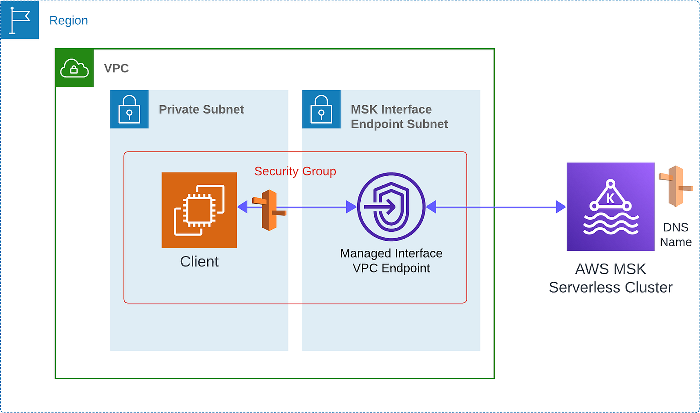
First let’s talk about the base case, communicating to the cluster while in the same VPC. You may be wondering why we say the same VPC even though it is a serverless cluster. Yes, this is true, but in order for us to reach the cluster created under our account and region, AWS automatically creates a VPC Endpoint for us to reach the serverless cluster like it’s within our VPC! The only thing we had to do in the below diagram was define a security group for our EC2 instances to communicate with this new VPC Endpoint.
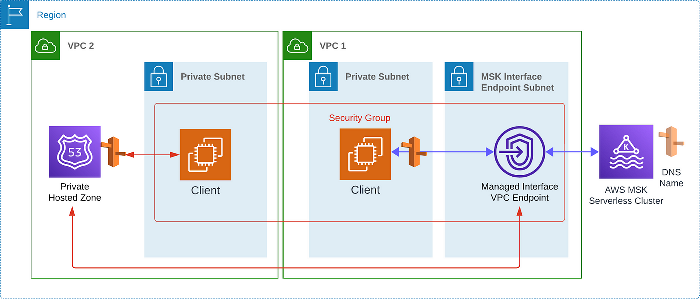
Now the more tricky integration, how to allow VPC 2 to connect to this MSK serverless cluster? A more concrete way to look at this problem is how to allow VPC 2 to connect to the above VPC Endpoint. Firstly, we expanded the security group attached to the VPC Endpoint to allow traffic from VPC 2. Then, we created a Private Hosted Zone in VPC 2 that will route the DNS name provided by our MSK cluster to the auto-created VPC Endpoint. In essence, this is exactly what AWS manages for us when connecting to the cluster within the same VPC. And voila, both VPCs can communicate with our MSK cluster!
Topic Creation
One thing to note about MSK Serverless instead of MSK is that it doesn’t support auto-creation for topics. Luckily, Segmentio’s Kafka-Go library provides wrappers for the topic creation APIs. We created a Kubernetes job that would send a create topics request for every topic. If a topic already exists, it does nothing, otherwise it creates the topic with the configuration options we provide. This idempotent operation makes it easy to create topics on our cluster whenever a new topic is added to our application.
Serverless also has a much more limited set of configuration options. Topics are the only way to customize the configuration of a serverless cluster, broker level configuration options aren’t available.
Conclusion
IAM Reset Tradeoff
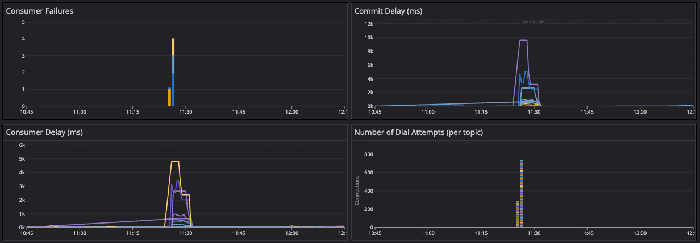
Before adding controlled resets, we saw huge latency spikes with the rebalances:
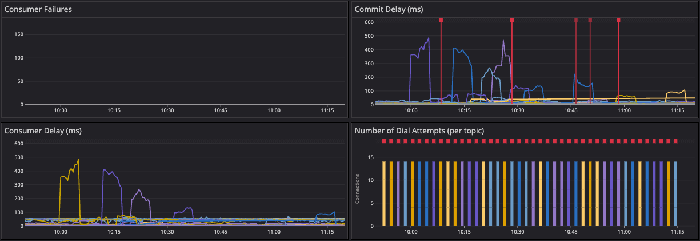
After implementing resets, the latency spikes were much more manageable and the connections were spaced out. Errors are also much less frequent:
The main downside of this method is the extra complexity of our Kafka consumer implementation. We have an extra goroutine for each consumer to wait for the next reset and need to track extra state. We are considering switching to long-lasting IAM credentials to avoid needing to refresh the credentials, but that is not considered best practice in terms of security.
Improvements: latency and resource utilization
Resource utilization reduction was honestly a very pleasant surprise once the migration was complete. Memory utilization for our microservices decreased on average by over 70%! And CPU utilization on average by 50%. But let’s look back and explain why the dramatic decreases. We narrowed the cause to confluent-kafka-go’s use of cgo. It seems well-documented that cgo is a powerful but very finicky tool and we think our migration supports this. (Reference: Blog 1 Blog 2) Memory management and low-level performance become exponentially harder to control when trying to work between these 2 languages under the Confluent library.
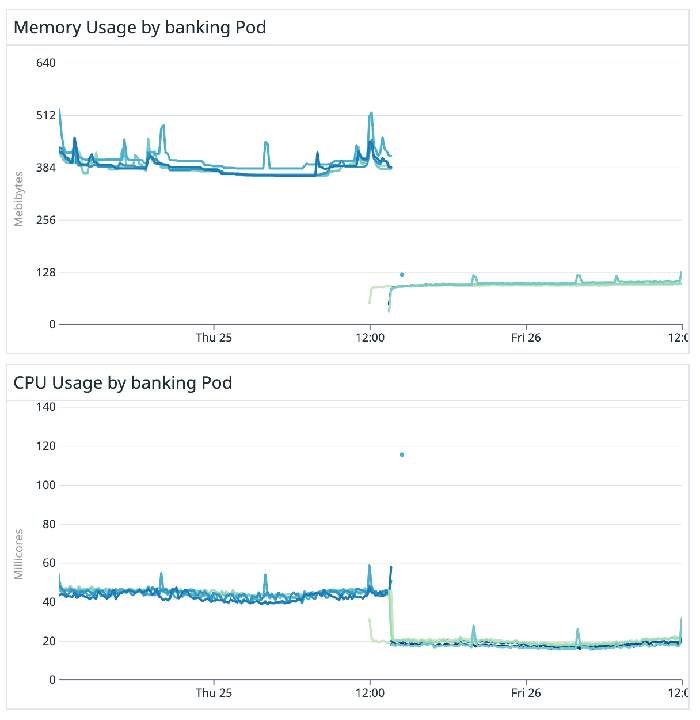
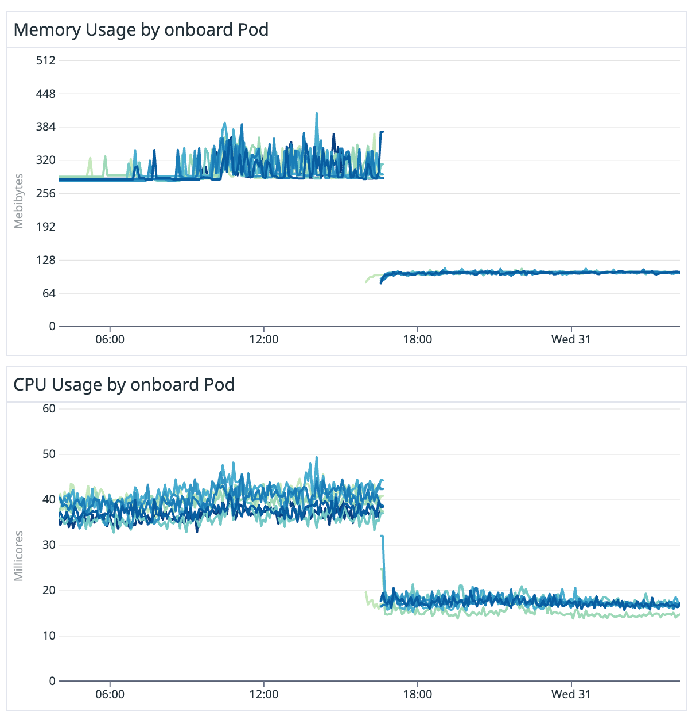
While one’s initial reaction may be that performance latency is worsened going from provisioned to serverless cluster, P99 consume latency dropped an average of 80%! Moreover, this is more impressive if you consider we measure consume latency from the time the message is created by the producer to the time it is consumed by the consumer. We attribute the success of this to most notably the finer control of Segmentio’s library on Transport layer configurations and its cgo-free source code.
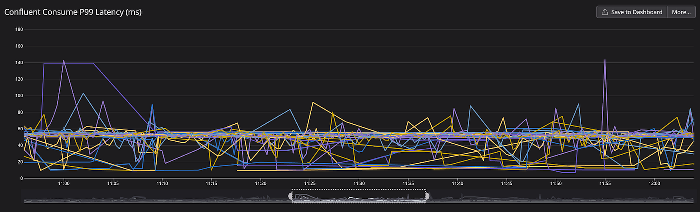
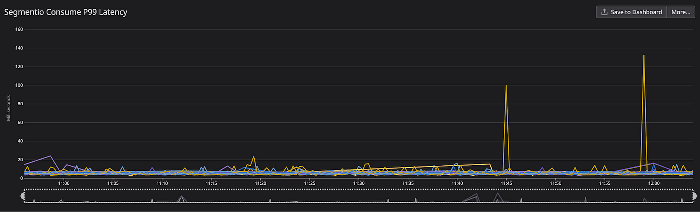
Closing Thoughts
Today, our Kafka infrastructure supports a myriad of use cases across our engineering teams and serves millions of messages a day with little to no issues. Thank you for reading if you’ve made it this far! You are probably excited about AWS, specifically MSK, and the intricacies of Segmentio’s Kafka Go library. If you want to work on interesting problems in infrastructure, consider opportunities at Imprint. You can find us at imprint.co/careers.