Debugging Spinnaker Connectivity Issues with EKS Clusters Across VPCs: A Journey Through AWS Networking
In a recent debugging journey, we encountered a puzzling connectivity issue: our deployment tool, Spinnaker, which operates in a backend EKS cluster, suddenly lost access to resources in another cluster used for our public gateway. With recent EKS upgrades underway, we initially suspected a security group misconfiguration. However, this wasn’t a typical connectivity issue as no recent changes could clearly explain it.
As we investigated, we found ourselves navigating the complexities of AWS cross cluster routing and subnet configurations in EKS. Each clue pointed us deeper into the architecture, leading to unexpected discoveries about ENI placement and routing behavior within AWS. This blog details our journey through these layers of troubleshooting, the insights we gained, and the lessons learned along the way.
Background
In our system architecture, we use two separate VPCs: one designated as the “Gateway VPC” for handling public traffic, and the other as the “Backend VPC” for private computation and data management. These VPCs are interconnected via VPC peering. Spinnaker, our deployment tool, is set up on a dedicated EKS cluster (CD EKS) within the Backend VPC and manages deployment tasks for both the Gateway and Backend EKS clusters.
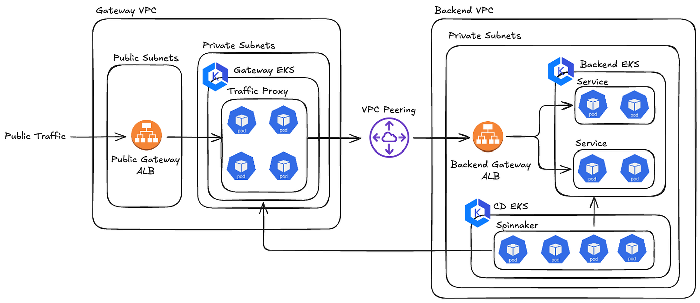
Earlier this year, we transitioned both the Gateway and Backend EKS clusters from a hybrid of public and private control plane to pure private control plane endpoints to enhance security. We configured the CD EKS cluster’s security group as an ingress source for both clusters, enabling direct communication with their private endpoints. This setup had been running smoothly until this incident occurred.
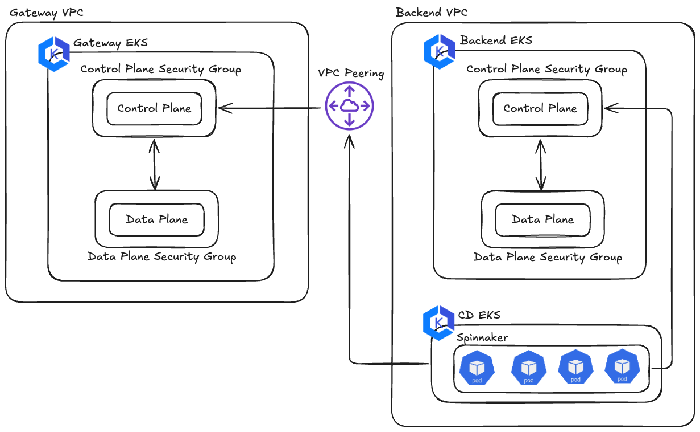
Facts Gathering
The problem first surfaced during a deployment, where our production Spinnaker instance was unable to list namespaces in the Gateway EKS cluster, while the Backend EKS cluster remained unaffected. We immediately began tracing logs to pinpoint the starting point of the failure. Given Spinnaker’s architecture, we focused on Clouddriver, as it handles all mutating calls to cloud providers and manages resource indexing and caching. We quickly spotted the error in Clouddriver’s logs:
2024–10–29 23:15:19.078 ERROR 1 — — [ Thread-26089] c.n.s.c.k.s.KubernetesCredentials : Could not list namespaces for account prd-api-eks-cluster: Failed to read [namespace] from : Unable to connect to the server: dial tcp 172.***.***.121:443: i/o timeout
After cross-checking the Gateway EKS API server endpoint, we confirmed that 172.***.***.121 was indeed one of the Gateway EKS API endpoint’s (the control plane) IP addresses:
➜ host <redacted>.gr7.us-east-1.eks.amazonaws.com
<redacted>.gr7.us-east-1.eks.amazonaws.com has address 172.***.***.121
<redacted>.gr7.us-east-1.eks.amazonaws.com has address 172.***.***.39
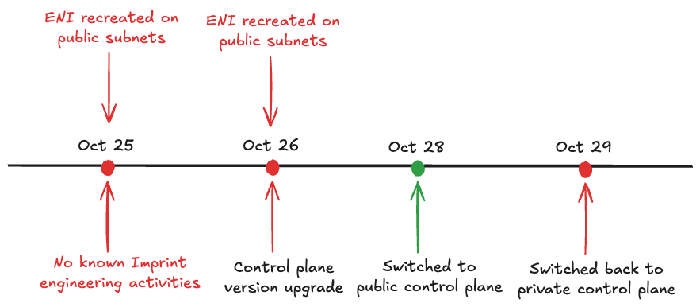
Interestingly, we noted a pattern in the errors: they began around Friday around 12:00pm, stopped briefly on Monday afternoon, and then resumed on Tuesday around 12:00pm.
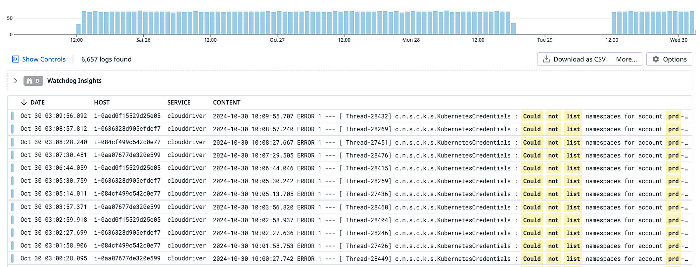
We created a timeline to visualize the pattern and aligned our known engineering activities to it.

Dive Deeper Into the Facts
We observed that the failure sequence began with an unknown trigger, as no engineering activity seemed to have caused it. However, the i/o timeout errors suggested that connectivity from the source to the target is blocked. We decided to focus on understanding why this connectivity issue occurred, hoping it would clarify the entire sequence of failures.
To investigate the connectivity issue, we used AWS Reachability Analyzer to trace the path between our Spinnaker pod and the Gateway EKS control plane ENI. The analysis below revealed expected results for the path from the Spinnaker pod to the Gateway EKS control plane ENI. However, we were surprised to find that the Gateway EKS control plane ENI was actually located in a public subnet, though the EKS was supposed to be fully private.
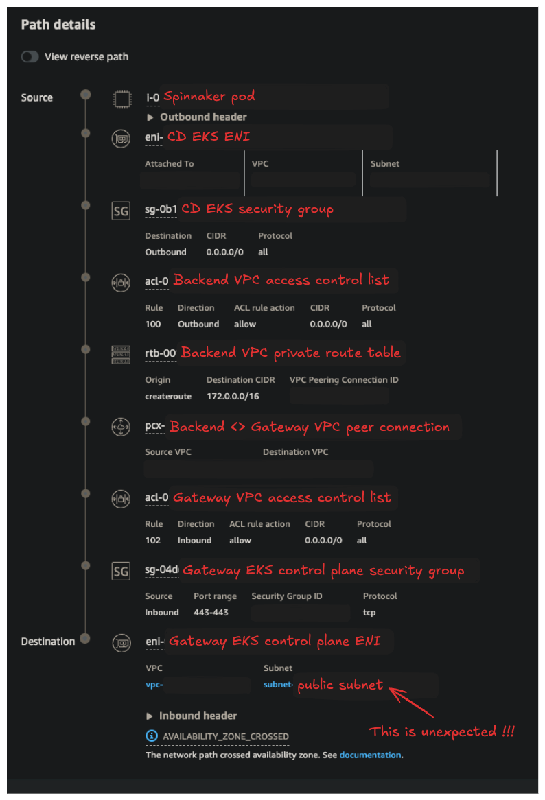
We then examined the reverse path, which confirmed the culprit: because the ENI was placed in a public subnet, the return path relied on the public subnet’s route table. Since our configuration doesn’t permit traffic from the public subnet in the Gateway VPC to the private subnet in the Backend VPC, the traffic was dropped due to the lack of a valid return route.
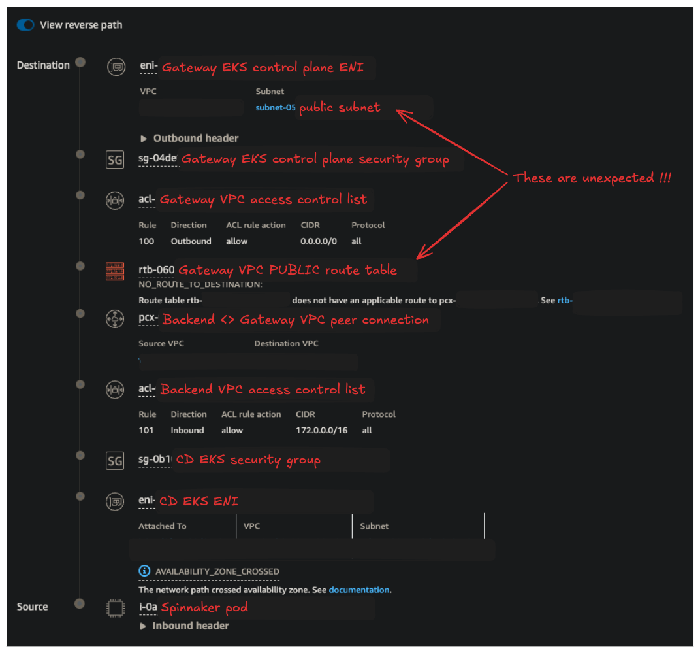
This brought us closer to the root cause, but two critical questions remained:
- How does EKS manage control plane ENIs, and why are they placed on public subnets?
- What was the unknown event that triggered this issue?
Eureka Moment
We started digging into EKS documentation, focusing specifically on how EKS manages its control plane ENIs. Eventually, we found a critical insight in the EKS networking requirement:
When you create a cluster, Amazon EKS creates 2–4 elastic network interfaces in the subnets that you specify.
Amazon EKS can create its network interfaces in any subnet that you specify when you create a cluster … When you update the Kubernetes version of a cluster, Amazon EKS deletes the original network interfaces that it created, and creates new network interfaces. These network interfaces might be created in the same subnets as the original network interfaces or in different subnets than the original network interfaces.
This pointed out a crucial detail: control plane ENIs are created in the specified subnets at the time of cluster creation and are recreated on these subnets during control plane upgrades. Armed with this clue and the observed failure pattern, we made 3 bold assumptions that could potentially explain the issue:
- Public subnets were included in the Gateway EKS cluster configuration.
- An undocumented event triggered an ENI recreation on October 25.
- We should observe ENI recreation events on October 25 and October 26, both creating ENIs in public subnets.
With these assumptions, we began testing each one. First, we reviewed our Gateway EKS setup and confirmed that public subnets were indeed included in the cluster configuration. It turned out we’d simply been lucky until now that ENIs had been assigned to private subnets, where cross cluster communication routing was correctly set up.
As we investigated why public subnets had been included, a comment in our Terraform code clarified the reasoning: “We supplied public subnets to EKS because we need to create a public ingress in the data plane.” This revealed a misunderstanding: the public subnets were mistakenly included for the data plane rather than the control plane, and thus we could safely remove them without impacting dependencies.
To verify assumptions 2 and 3, we searched AWS CloudTrail for all CreateNetworkInterface events from October 20 onward. Sure enough, the results aligned with our assumption:
To confirm the undocumented trigger for ENI recreation, we contacted AWS support to see if any AWS-initiated changes had occurred on October 25. After a day, we received the following confirmation:
EKS control plane is fully managed by AWS. I reviewed resource status from an internal tool, I can confirm that EKS control plane node replacement has occurred due to continual updates of the API server for high availability in the same timeframe above. EKS ENI replacement occurred when EKS performed continual updates to maintain stable service.
Due to AWS security policies, we’re limited in the level of detail we can share. However, to support your understanding as much as possible within these constraints, here’s what we can explain:
The EKS control plane is fully managed by AWS and runs on EC2 infrastructure, requiring ongoing maintenance similar to other EC2 based services. This includes managing OS-level patches, internal AWS tools and processes, hardware issues, and adjustments to meet usage demands.
AWS support confirmed that an update in the EKS managed control plane triggered the ENI recreation during that period as part of routine maintenance to ensure stability, similar to other managed EC2-based services. This detail, however, was not clearly outlined in the EKS documentation.
At this point, we had validated all our assumptions and identified the root cause: unintended public subnets were associated with the Gateway EKS cluster. We resolved the issue by removing the public subnets from the EKS cluster’s subnet pool, bringing our troubleshooting journey to a successful close.
Lessons Learned
This debugging journey highlighted some crucial lessons about AWS EKS networking and cross-cluster connectivity:
- Understand managed service architecture and follow best practices. Managed services like EKS simplify infrastructure management but come with architectural nuances that can introduce unexpected behaviors. By understanding the architecture of these services thoroughly and adhering to recommended best practices, you can prevent surprises and streamline troubleshooting when issues arise.
- Expect the unexpected with AWS managed services. AWS managed services often handle infrastructure components, such as ENI placement, in ways that are not entirely transparent. This debugging experience reminds us of the importance of understanding managed service behavior and configurations thoroughly, as assumptions can easily lead to connectivity problems.
- Document intentions clearly. The Terraform comment suggesting the introduction of public subnets helped us remove the concern of modifying legacy code. Clear documentation of configuration purposes can prevent these misinterpretations and save time when troubleshooting.
- Leverage AWS tools for in-depth analysis: AWS Reachability Analyzer and CloudTrail were instrumental in identifying and confirming connectivity and resource changes, respectively. AWS Reachability Analyzer helped us trace unexpected routing paths, while CloudTrail allowed us to pinpoint ENI recreations and correlate them with connectivity issues. Together, these tools offered crucial visibility in debugging the issue.
Ultimately, this debugging journey emphasized the importance of a robust understanding of cloud network architecture, especially for complex multi-cluster setups. As we move forward, we’re applying these lessons to ensure smoother connectivity and fewer surprises with future infrastructure changes. If you want to work on interesting problems in infrastructure, consider opportunities at Imprint. You can find us at imprint.co/careers.