The evolution of Kubernetes resource management at Imprint
Imprint is embracing cloud-native and building its entire realm on Kubernetes. Along the way, we have tried different practices and gradually found the ones that fit our needs best. In this post, we share our journey to a more scalable and robust Kubernetes with you.
Different worker groups for different services
We started our topology by assigning one worker group per service:
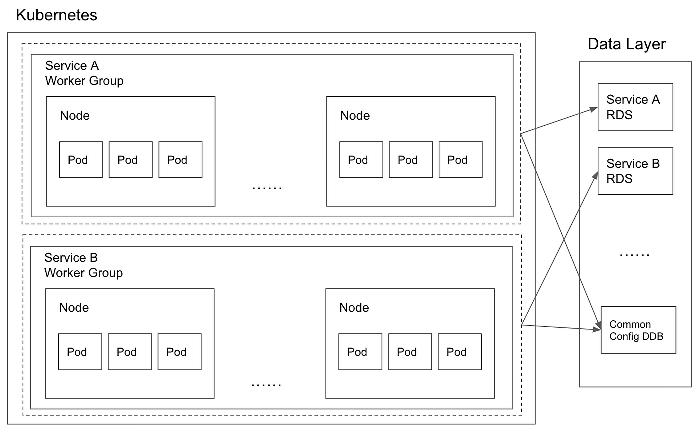
Each worker group is an Auto Scaling Group (ASG) resource in AWS. We rely on Security Group to do data layer access control on the network level, and Identity Access Management (IAM) for RBAC. Although this topology provides great service isolation, we soon began to realize the defects of such a design
As a fintech company, stability is always our top priority. To achieve high availability, we created pod redundancies, aka replicas, in different nodes and different AvailabilityZones, resulting in the following topology:
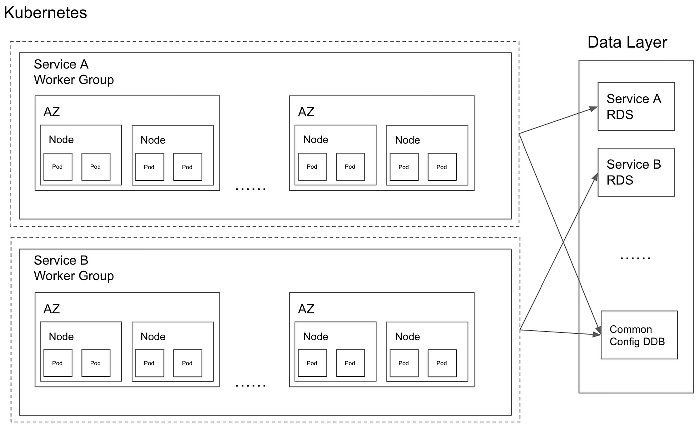
Since we are a young startup, traffic volume is still ramping up with our growing business. As a result, each node hosts only the minimum number of pods we set, and therefore exists with very low utilization. However, with the growing complexity of our business logic and engineering requirements, we continue to introduce more services, creating more under-utilized nodes that are not cost-efficient.
Single worker group for all services
The solution to this problem is quite straightforward: we want to put as many pods into the same node as possible. This leads to two challenges:
- How do we do data layer access control?
- How do we ensure that different services’ pods won’t compete for system resources with each other?
Pod level access control
We make use of IAM roles for service accounts provided by AWS. If you are interested in how it was made possible internally, here’s a very detailed deep dive explanation.
With this feature, we can specify permissions on the pod level, and thus control data access for services.
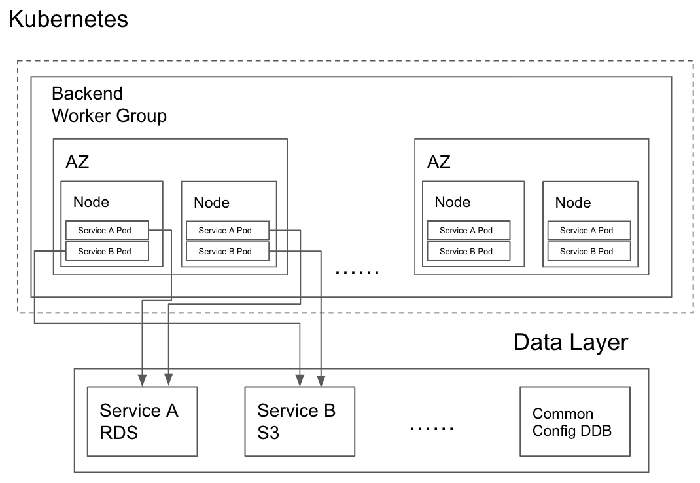
Resource management practice
At Imprint, we have developed one key principle in our practice: always make pod request memory equal to the limit memory.
It’s important to understand two facts about the Kubernetes scheduler:
- The Kubernetes scheduler uses the request value to determine whether a pod should be placed on a particular node;
- Unlike the CPU limit which would keep the pod running at the limit and simply throttles CPU usage, a pod would be killed due to OOM (Out Of Memory) if it hits the memory usage limit.
Due to Fact #1, it’s possible to schedule pods with more than 100% memory limit on a node, so some of the pods might be starved for resources while others are running close to their limit. That is, some of the pods might be affected by ‘other unknown neighbors’.
For example, let’s say we have two services, and each service is running with one pod. Both of the services require a minimum memory of 500Mi at non-peak time, and 900Mi at peak time. With this requirement, it’s valid to set the resource requests at 512Mi and limits at 1Gi. When both pods are required to be scheduled on a node of 1Gi memory, they will coexist with each other nicely during non-peak time. However, at peak time, one of the pods will occupy most of the resources in the node, leaving the other pod lacking in resources.
To mitigate the noisy-neighbors problem, we therefore set the resource request and the resource limit to be the same. With the two facts mentioned above, each pod will only occupy a determined number of maximum memory.
Scaling policies
After setting the initial resource request and limit, we still need to apply proper scaling policies to adapt to the traffic changes, i.e. expand the number of pods to share traffic when traffic volume is high, and shrink the pods to save resources when traffic volume is low.
To accommodate our topology, we employ Kubernetes Horizontal Pod Autoscaler (HPA) and Cluster Autoscaler (CA) to achieve elasticity. HPA allows users to specify various scaling conditions, such as percentage of CPU (used / requested), percentage of memory (used / requested), and/or other external metrics. When one or more condition(s) satisfy, HPA will add more replicas based on how much the current value differs from the expected value. CA listens to Kubernetes scheduler events, and whenever there are unscheduled pods due to insufficient resources, new nodes will be added by updating the desired number in the worker group’s ASG.
An intuitive explanation of the scaling policy would be box packing. Each pod can be seen as a small container with fixed dimensions, and we are trying to fit it into a larger container, aka, the node. When the small container (pod) is almost full, we will add more small containers to the large container. When the large container (node) doesn’t have enough room for the small container, we will add more large containers.
Topology constraints
While it seemed that the resource management problem had been nicely solved, soon we realized a new resource dispatch problem on the topology level: when deploying pods and no additional strategies are provided, the Kubernetes scheduler was not intelligent enough to spread the pods evenly across the topology. That is to say, it’s possible that all replica pods for service are scheduled on the same node, which creates a single point of failure for that service.
We solved this problem using pod topology spread constraints natively supported by Kubernetes. This feature allows us to specify our strategy to spread our pods across the entire topology, including any customized topology labels. In order to achieve higher availability at Imprint, we force pods to spread across hosts and availability zones as much as possible.
Handling node termination
So far, our Kubernetes cluster looks good. It runs pods with high node utilization, every pod has a linked service account for permission control, pods spread evenly across topology, and pods can scale properly. However, the good days only last until the worker group starts to scale-in due to low traffic.
As explained above, CA will trigger ASG actions according to the Kubernetes resource status. Since the ASG is an AWS resource but not a native Kubernetes component, when terminating a node, it won’t care what is currently running inside the node. If this termination is not handled properly, the pod may not stop gracefully and thus cause unexpected errors.
To handle node termination events properly, we introduced Node Termination Handler (NTH) to our Kubernetes clusters. With the help of NTH, we observed that our applications will now be terminated gracefully when ASG scale-in events are triggered.
Separation of system pods
So far, all of our work has revolved around service pods management. We’ve left all system pods running with their default settings, and scheduled them as if they were normal service pods.
Now consider the following situation: Let’s say some service code has a bug that causes a serious memory leak. When this code is triggered, all available memory will be consumed. Let’s also say that, unfortunately, the engineer who’s in charge of releasing this commit accidentally removes the CPU and memory constraints for the pods.
The consequence of the buggy code and lack of resource constraints would cause all nodes that have this service running to fall into an unavailable state due to insufficiently allocated memory. And the damage wouldn’t stop there. Since all system pods, including coredns pods (which is the DNS proxy used in Kubernetes for domain name resolution), are scheduled with no extra strategies, all of them would likely be scheduled on those unavailable nodes. Therefore, DNS would become unavailable as well, which would bring the entire cluster down.
This scenario sounds the alarm for us to have better isolation for our system pods. We want the system pods to be managed on a separate worker group so that they won’t compete with the pods handling the business workload, and can be maintained and scaled based on their own needs.
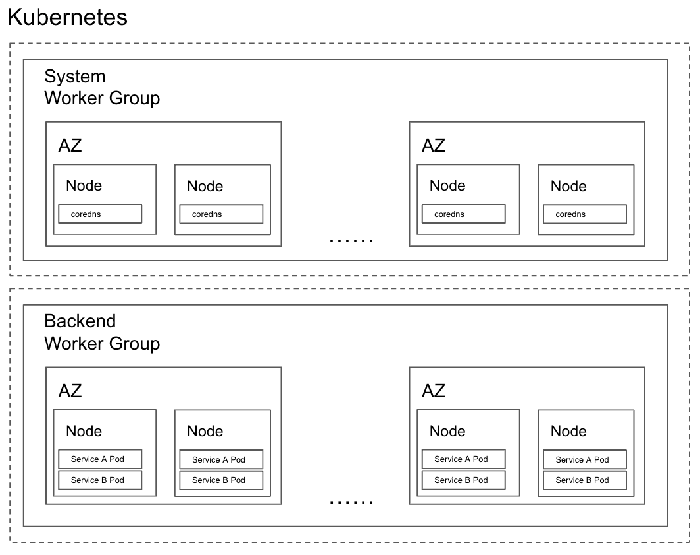
Summary
And that’s the evolution of our Kubernetes resource management thus far–how we thought about gradually developing our Kubernetes to become more scalable and robust.
As Imprint expands rapidly, we are continuously improving our infrastructure to support our growing needs. If you are interested in building Kubernetes and witnessing your talent being used by hundreds of engineers, thousands of merchants, and millions of users, we are the right place for you to unleash your potential. You can find us at talent@imprint.co or imprint.co/careers.